Claude Opus in a loop can now iteratively improve product KPIs by itself, with little to no human intervention. This new capability means that the first startup in a market to completely close the loop on their KPI improvement (conversion, activation, revenue) will have compounding metric improvements that human teams cannot meet or exceed.
This is the new moat for SaaS: it's not the death of software, it's the rebirth, and self-improving products are the future of apps.
The best teams are closing the loop themselves
One year ago, Basedash, a BI startup, connected an AI agent to Stripe and their product database and triggered it to run daily with the goal of optimizing product activation:
We've been getting these messages from the AI every day since June, and we've simply been implementing any suggestions that seem reasonable. Takes our engineering team a few hours a week...
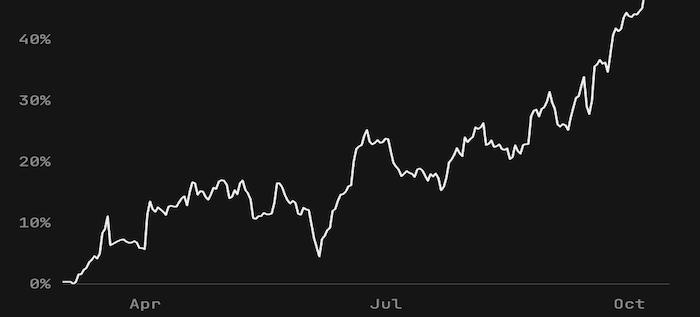
With the full context of real users activating onto Basedash, the agent could see where users fell out of the activation funnel and could suggest ideas on how to improve this, every day. They scheduled it daily and Basedash ended up 10x'ing their activation rate after three months. (the asterisk here being the engineering team implemented the changes and filtered for "good ideas")
Other companies are building feedback loops like this into their product engineering stacks. AI SRE startups (like Resolve AI) are identifying errors in prod and automatically fixing them, AI CRO startups manage A/B tests on landing pages automatically, and we're starting to see companies fix frontend UI bugs from session replays automatically.
The new moat for apps is a positive feedback loop (recursive self-improvement)
There are three components to automating a positive feedback loop that improves your product (in this case by writing code):
- Positive/negative signals about product quality that refresh frequently (KPIs like conversion, activation, engagement, revenue)
- Ability to generate suggestions targeting specific aspects of the signal, LLMs with "big model smell" are good at this (Opus/Grok)
- Implementing and merging experiments with minimal latency (less than 24 hours) which requires AI PR review, a robust CI/CD pipeline, and an culture of experimentation
Given that LLMs can now continuously work on the same task for 10 hours, now is the time to build the loop in your startup and take advantage of longer horizon tasks.
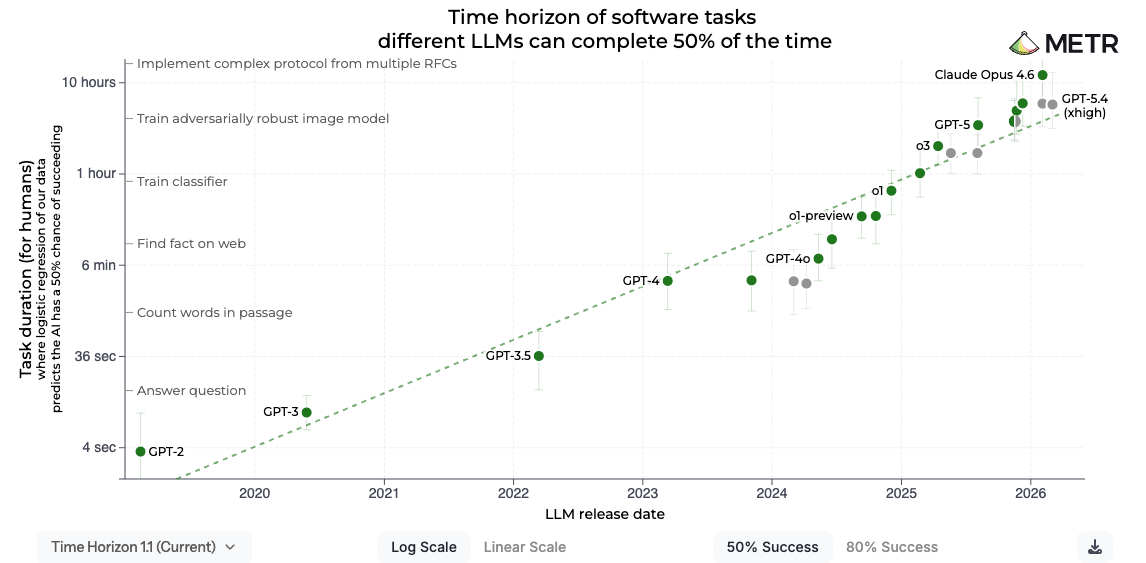
In our experience, the optimal cadence for this is a daily iteration which is tight enough of a self-improvement loop that it's a real and genuine moat over competitors. Probably, the first startup to fully close the loop in their market will win.
The requisite tech stack for closing the loop
- Product analytics: MixPanel MCP/Amplitude MCP/PostHog MCP are the defaults here. The agent needs full unrestrained access to your analytics data and it must be in a format that lets it explore.
- Frontier models with taste, basically Opus or Grok in our experience. This is actually the biggest gap right now, frontier models are way better at coding than they are at coming up with good ideas. This is where we've invested most of our time.
- Full sandbox that's customized to your codebase for implementing suggestions (seems like most of the sandbox providers are comparable but Modal is great and E2B exists)
- Automated PR review to reduce the lift needed to actually merge the change onto main. We've had good luck with Greptile and Devin. This is basically mandatory.
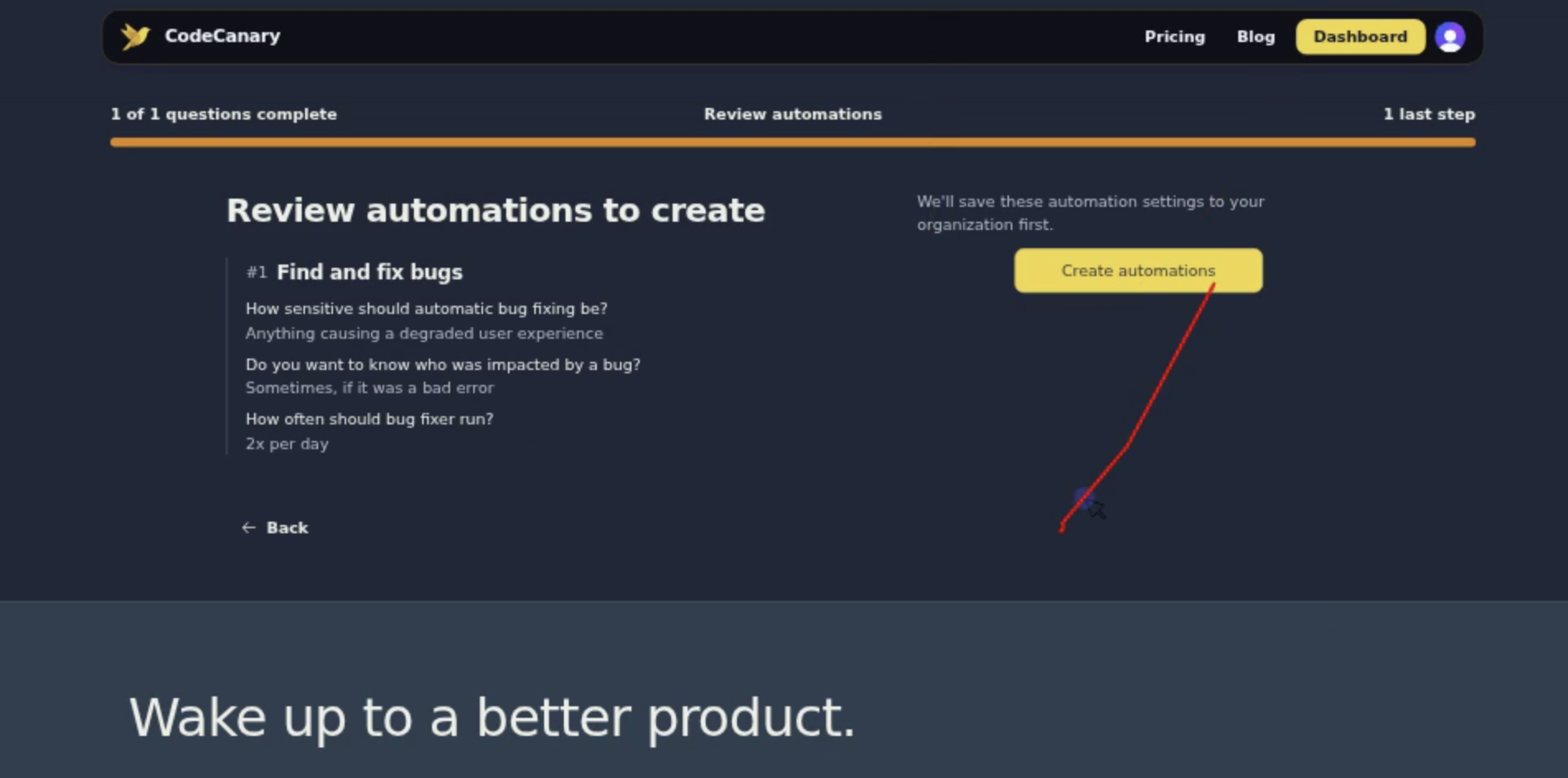
People also like putting free-form notes into the context window, so Pylon tickets, notes from Granola, etc. We (CodeCanary) in particular add session replay understanding and have invested deeply in our integration with rrweb-based replays (screenshot above). Engineering the right context for your self-improvement agentic loop is key because it's normally deeply tied to what the end user of your app sees. For CodeCanary, our Slack bot is a key part of interacting with our product (e.g. approving the creation of pull requests), so we have everything properly instrumented so interactions end up in our PostHog ClickHouse database.
While I think having the right harness to run this automation is important in the short term, it may be possible in the future to just instruct Mythos to "make product better, make no mistakes" and set it up on Claude Code Routines, but right now we've found a good system prompt and harness goes a long way in improving performance on real products.
SaaS isn't dead: closed loop programming is the rebirth of SaaS
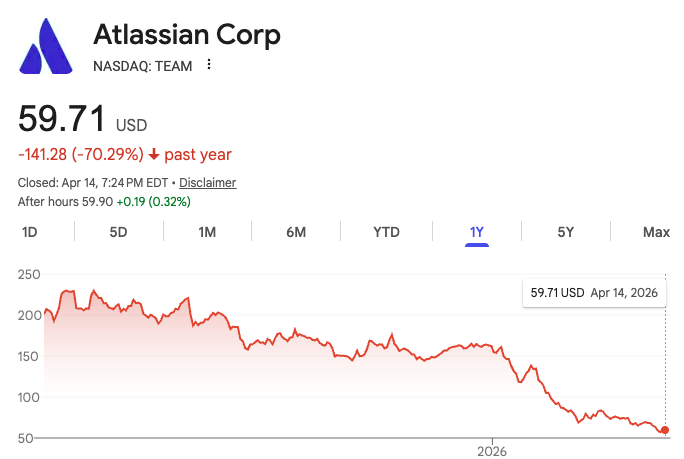
I don't really believe that we're experiencing the death of SaaS in general because Saas isn't just the Atlassian stock price (yikes!).
There will obviously be 100x more software in the future than there is today. The GitHub COO already said that commits are on track to be up 14x YoY. But the tactics to build a dark software factory are only in use at a few teams.
A/B tests should be considered an agent skill that unlocks verifiable code changes that have business impact. Engineering teams that are moving the fastest right now have built verifiable environments for their code. StrongDM cloned Slack just to test their app and essentially created a "dark software factory" in which software builds itself.
An interesting way of looking at A/B tests is an extended pull request review process. For reliability, you create the pull request, merge to main, and if the error rate spikes you rollback the change. The same is true here: revert the variant to control if the variant doesn't measurably outperform control. This double review process lets you move faster, ship more code, and drive KPIs up.
What is CodeCanary?
If you read this far, you might be interested in my product.
CodeCanary automatically improves your product based on your product analytics. We connect to PostHog and your GitHub repo(s) and open pull requests that fix bugs, improve conversion, and learn from your best users. It costs $500/month for 3 daily automations. You can self-onboard here or schedule a Zoom call with us to learn more.